DeepSeek vs. Occident. Avantatge estratègic o amenaça temporal?
 Per Àlex Fusté
Per Àlex Fusté
“DeepSeek ha aconseguit superar a ChatGPT a les botigues mòbils d'aplicacions, i també en proves de rendiment i raonament amb el seu model R1, i a una fracció del cost d'entrenament”.
Aquesta frase ha corregut com la pólvora entre els inversors del món i, com ja sabran, ha provocat un autèntic terratrèmol en els mercats; especialment en el sector tecnològic occidental. El que posa nerviosos als inversors és l'última part de l'afirmació: “a una fracció del cost d'entrenament”. Bé. He escoltat frases com “es tracta d'un model més eficient basat en l'aprenentatge per reforç”, no sé si en un intent d'impressionar-me. L'aprenentatge per reforç (Reinforcement Learning), i específicament l'Aprenentatge per Reforç amb Retroalimentació Humana (RLHF, per les seves sigles en anglès), ja era àmpliament utilitzat en els models de llenguatge més avançats a Occident fa més d'un any. OpenAI va introduir el RLHF de manera prominent amb GPT-3.5 i GPT4.
Observació 1: Transferència de costos.
És necessari saber que la qüestió del menor cost pot tenir a veure amb alguna cosa que no és en absolut disruptiu. És possible que DeepSeek, igual que Copilot, no sigui un model autònom complet. Copilot (amb només 10 milions de cost d'entrenament) està entrenat en Codex, un model desenvolupat amb anterioritat per OpenAI i derivat de GPT-3. Significa que quan Copilot surt a la llum, OpenAI ja havia absorbit prèviament la major part del cost d'entrenament del model basi, deixant a Microsoft el simple treball d'ajustar el model (fine-tuning) per a tasques específiques relacionades amb el codi. Podem derivar d'això que el model de IA Copilot té, al final del procés, un cost significativament menor? No. En absolut.
Encara que Deepseek sigui de codi obert, aquesta IA podria estar beneficiant-se d'una casuística similar a la de Copilot, mitjançant l'ús d'un model basi preexistent. DeepSeek podria estar basat en un model preentrenat de codi obert, com LLaMA 2, Falcon o fins i tot GPT-NeoX. Significa que Deepseek està realitzant de facto una transferència de costos, ja que els costos associats al model basi haurien estat absorbits per l'organització que va desenvolupar aquest model original. Llavors, DeepSeek, igual que Microsoft, només hauria de realitzar el fine-tuning en un conjunt de dades específiques, que és molt menys costós que entrenar un model des de zero. Això és bastant plausible, perquè hi ha startups que solen recórrer solucions en el núvol per a entrenaments específics basats en models preexistents, la qual cosa redueix la despesa inicial. Quina és la diferència entre Copilot i Deepseek? Que Microsoft va pagar el 2019 1.000 milions de dòlars a Open AI, i el 2023 altres 10.000 milions addicionals. Entenc que en concepte d'aquesta 'transferència de costos'.
Caldrà esperar i veure, però se'm fa molt difícil pensar que, després de dècades de treball en matèria de xarxes neuronals, deep learning i, finalment la IA, els creadors originals d'aquests models permetran que aquesta situació de “entrenament per transferència” es materialitzi donant lloc a models millors, sense incórrer en els costos associats.
Però pot realment una empresa com Deepseek posar en escac als desenvolupadors occidentals? Depèn de la capacitat que aquests últims tinguin per a defensar-se. En aquest sentit, han de saber que els desenvolupadors dels models basi tenen diverses estratègies per a protegir el seu treball i evitar que tercers creïn models millors mitjançant l'ús d'un model basi preexistent. Aquestes defenses tenen a veure amb:
1. Restriccions de Llicència.
2. Protecció a través de Patents i Propietat Intel·lectual (que podrien donar lloc a multes bilionàries).
3. Liderar en Innovació Contínua amb models en evolució constant: Els creadors originals solen mantenir un avantatge competitiu en llançar iteracions constants dels seus models, creant una important barrera tècnica per a aquells que intenten competir mitjançant "fine-tuning" (o còpia). Això és el que probablement passaria en aquest cas. Al cap i a la fi, la IA que tenim avui és la pitjor que tindrem. Què importa llavors que un competidor iguali els models actuals mitjançant entrenament per transferència, si en poc temps (i com és previsible) apareixeran nous models més potents?
4. Infraestructura exclusiva: OpenAI i Google tenen accés a recursos de maquinari i programari optimitzat que els permet continuar liderant la carrera i crear noves versions.
5. Models protegits contra extracció: Implementar tècniques per a dificultar l'extracció de coneixement del model (model robat), com 'adversarial training'.
Observació 2: Subsidis
Un aspecte rellevant a considerar en l'anàlisi del cost reduït d'aquest model d'intel·ligència artificial és el possible efecte de subvencions governamentals, un fenomen particularment freqüent a la Xina, especialment quan Pequín estableix un “Pla Superior” per a uns certs sectors, com el de bateries, EVs o panells solars. No descartaria la possibilitat de l'existència de fortes subvencions que ajudarien a emmascarar els costos.
S'ha assenyalat que el desenvolupament de DeepSeek compta amb el suport explícit d'un hedge fund denominat High-Full de mà. No obstant això, aquesta situació resulta inusual en el context d'Occident, on els hedge funds no solen exercir el paper d'impulsors principals en el desenvolupament d'empreses tecnològiques. Aquest tipus de fons solen centrar-se en estratègies d'inversió que maximitzen el retorn financer a curt o mitjà termini, en lloc d'assumir els riscos inherents al desenvolupament tecnològic a llarg termini, que solen ser costosos, incerts i de lenta maduració. Els Hedge Funds es dediquen a l'arbitratge, trading algorítmic o estratègies macroeconòmiques. També està la pròpia asimetria de coneixements, alguna cosa que sol mantenir als Hedge Funds ben allunyats de projectes que no entenen i que requereixen d'una experiència tècnica profunda, així com d'equips especialitzats. Areas on els Hedge Funds solen mancar de competència. Un podria tenir la impressió que el suport d'un Hedge Fund com High-Fyer no sigui completament independent, sinó que actuï com un vehicle per a canalitzar subvencions públiques significatives. Aquest tipus de dinàmica, si es confirmés, podria representar un cas evident de dúmping i pràctiques empresarials qüestionables des del punt de vista ètic i comercial. Aquest escenari no sols erosionaria l'equitat en la competència global, sinó que probablement desencadenaria una resposta formal per part de les autoritats reguladores a Occident i d'organismes internacionals com l'Organització Mundial del Comerç (OMC). La implicació de fons públics ocults després d'intermediaris financers posaria de manifest una estratègia potencialment deslleial, la repercussió de la qual en l'equilibri comercial i tecnològic seria motiu d'escrutini internacional.
Observació 3: Estem comparant adequadament?
Un aspecte crucial a considerar en l'avaluació comparativa de models d'intel·ligència artificial és l'amplitud de les seves funcions. Si DeepSeek està dissenyat per a tasques específiques, com a cerca avançada o anàlisi predictiva, és raonable esperar que els seus requisits computacionals siguin significativament menors en comparació amb models generalistes com GPT-4, l'arquitectura dels quals està optimitzada per a abordar una àmplia gamma de tasques. Aquest enfocament especialitzat podria explicar diferències en eficiència i cost. No obstant això, una comparació rigorosa requereix una anàlisi més detallada de les seves capacitats i objectius, ja que actualment no és evident si estem tractant elements realment equivalents.
Observació 4: Quin seria el veritable risc per a les tecnològiques occidentals?
Una possible explicació per a la reducció de costos d'entrenament podria residir en l'ús de maquinari de nova generació, específicament GPUs o TPUs desenvolupades a la Xina, que ofereixen un rendiment superior en mètriques clau. Aquestes mètriques inclouen una major capacitat de càlcul (Floating Point Operations Per Second, FLOPs), una eficiència energètica significativament millorada (FLOPs per watt) i menors nivells de latència (el temps requerit per a processar una tasca específica). En altres paraules, si els menors costos d'operació del model DeepSeek deriven de la creació de nous superchips que superen a les solucions actuals de Nvidia, això representaria un desafiament fonamental no només per a Nvidia, sinó també per al lideratge tecnològic d'Occident. Tal avanç implicaria un canvi significatiu en la competitivitat tecnològica global i obligaria a un replantejament estratègic en la indústria de semiconductors.
Conclusió. Motiu per a l'alarma?
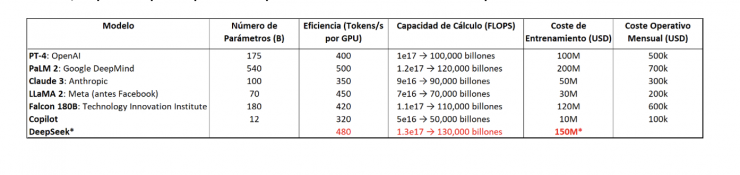
La materialització d'un risc real relacionat amb la supremacia de la Xina en semiconductors requeriria evidència concreta de què disposa de xips avançats superiors als actuals estàndards de la indústria. No obstant això, el consens predominant entre els experts en semiconductors indica que, encara que la Xina ha aconseguit avanços notables en dades i algorismes, continua depenent de la tecnologia estrangera pel que fa a semiconductors avançats.Una anàlisi destacada el 2023 per Ben Buchanan, de la Universitat de Georgetown, publicat en Le Grand Continent, assenyala que la Xina manca de capacitats significatives en la fabricació de xips lògics avançats i continua sent dependent del disseny de programari i maquinari provinent dels Estats Units. Si bé és cert que els avanços tecnològics en aquest sector són dinàmics i ràpids, i que la informació de 2023 podria haver quedat desactualitzada, un article més recent de Time (agost de 2024) reafirma aquesta bretxa tecnològica. Segons aquesta publicació, una recerca recent confirma la disparitat considerable en la possessió de xips avançats d'intel·ligència artificial, amb els Estats Units dominant l'accés a tecnologies d'avantguarda com la NVIDIA H100, mentre la Xina manca d'aquestes capacitats.De ser cert aquest panorama, el gran risc associat al desenvolupament de "superchips" a la Xina quedaria, almenys ara com ara, significativament mitigat. Aquest context reforça la percepció que, encara que la Xina està avançant en el seu ecosistema tecnològic, la supremacia en semiconductors avançats continua sent una barrera estratègica que afavoreix als Estats Units.A continuació, presento una taula que detalla els principals paràmetres d'eficiència i cost dels models de IA més destacats en el mercat. En relació amb el cost d'entrenament del model més recent de DeepSeek, cal destacar que aquesta xifra és una estimació, ja que l'empresa no ha proporcionat informació oficial sobre aquest aspecte. La projecció es basa en diverses premisses: ús de xips comercialitzats i disponibles en el mercat actual, partint d'unes suposades capacitats i eficiència que el posicionarien com a comparable a models avançats com GPT (segons reportis preliminars de diverses fonts). En aquestes condicions hipotètiques, el cost total d'entrenament per a DeepSeek s'estima en 150 milions de USD. No obstant això, aquesta estimació deixa obertes dues qüestions clau: Si DeepSeek empra maquinari innovador i de major rendiment, la qual cosa podria justificar un cost menor i una superioritat permanent. O si la seva competitivitat es deu a una transferència de costos a causa de l'ús de models preentrenats. En tal cas, la presumpta superioritat podria ser circumstancial i temporal.
*
Notícies relacionades

Acord entre Google Cloud i Andorra Digital que obre la porta que el país tingui un núvol sobirà

El programa de digitalització d’empreses inclourà ajuts per implantar la intel·ligència artificial